Most modern environments actually support working with unicode. But from there to use this in the code has a large space. The first point to consider before thinking about aesthetics and good practices is whether your language supports this. Most define a finite (and small) set of characters from which the source code must be composed. It is usually a subset of ASCII. For example, the C standard reads as follows (C11, 5.2.1 / 3):
Both the basic source and basic execution character sets shall have the following
members: the 26 uppercase letters of the Latin alphabet
A B C D E F G H I J K L M
N O P Q R S T U V W X Y Z
the 26 lowercase letters of the Latin alphabet
a b c d e f g h i j k l m
n o p q r s t u v w x y z
the 10 decimal digits
0 1 2 3 4 5 6 7 8 9
the following 29 graphic characters
! " # % & ' ( ) * + , - . / :
; < = > ? [ \ ] ^ _ { | } ~
Using anything outside of this would be invalid. A compiler can accept, of course. And the majority accepted. But if you want a portable code that will work on any platform, you should restrict yourself.
Another problem is the file encoding. It may happen that two files from the same program are saved with different encodings (for whatever reason). Visually you will see the É character in both, but at the time of execution, it may be that the compiler / interpreter sees different identifiers there. In the end you will have a fairly difficult error to crawl, since the error message will not help.
A language that broadly supports writing code with non-ASCII characters is Ruby. The parser and other tools have been built with this in mind and there is no limiting set of allowed characters. This makes way for some interesting things, as the article demonstrates. Unicode Whitespace Shenigans for Rubyists by Peter Cooper:
Using a unicode symbol for space (same as of HTML):
link
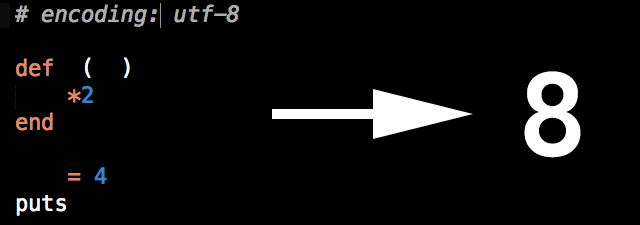
It is not seen as a space, it becomes part of the identifier. Lets you write something as confusing as this:
link
Since we have a fullness of space characters to use:
link
Using unicode in a codebase opens space for some very tricky bugs and crawling bugs. Another clear problem is trying to copy and paste the code into different tools. You never know what might happen.
Technical problems aside, there is always the question of language (the spoken one). If it's a large project, or it turns out to be opensource, it's always recommended to use English in the code, abolishing unicode usage.
In a small project with a team of few developers, there is plenty of room for rules to be defined and conventions of their own created. If there is an agreement between all, there is no reason not to. Remembering to always weigh the pros and cons of adopting this style.
One case that I have seen happen and which I consider to be somewhat valid is at the time of writing tests. In many frameworks you define a function / member / method that will be a block of asserts to be executed. When a fault, the name of this function is usually displayed on the screen as the name of the test that failed. Since this is a function you never explicitly call, using spaces-unicode in the name might be interesting. It will make the error output much more readable.






{kind=link}
{kind=link}
{kind=link}